1 导言
本文解读的是 J. Thorben Frank、Stefan Chmiela、Klaus-Robert Müller 与 Oliver T. Unke 发表在 Nature Machine Intelligence(2026, 8:388-402)的论文 Machine learning global atomic representations with Euclidean fast attention(DOI: 10.1038/s42256-026-01195-y)。
神经网络势能面(neural network potential, NNP)是一类服务于分子性质预测与分子动力学模拟的机器学习方法。它的目标是在远低于从头算电子结构方法的计算成本下,尽可能接近密度泛函理论(DFT)等量子化学方法的精度。这个方向的一个重要起点是 Behler 和 Parrinello 提出的高维神经网络势:用原子中心对称函数描述每个原子的局部化学环境,再把体系总能量写成各原子能量贡献之和。
后来的 SchNet、DimeNet、NequIP、MACE、ViSNet 等模型把这种原子中心思想发展成图神经网络或等变消息传递框架:原子是节点,原子间相对位置和局部邻接关系决定消息如何传播。这类方法之所以高效,很大程度上依赖于局部截断半径;只有截断范围内的原子对会直接交换信息。这个假设一方面把计算复杂度控制在接近随原子数线性增长的范围内,另一方面也带来了这篇论文要处理的核心困难:许多物理化学现象并不完全局域,静电、色散、非共价相互作用、电荷转移和电子离域效应都可能跨越局部 cutoff。
自 2017 年 Attention Is All You Need 发表之后,注意力机制逐渐成为处理全局依赖关系的通用模块。它可以被理解为一种在全连接图上进行信息聚合的方式:每个节点都根据 query-key 相似度从所有其他节点读取信息,而不是只接收固定邻居的消息。这种机制已经在自然语言处理、计算机视觉和具身智能等领域成为基础组件;对原子系统而言,它的吸引力也很直接,因为许多化学和材料性质本来就取决于远距离原子之间的相互影响。
困难在于,三维欧氏空间中的注意力不能只处理抽象 token 之间的相关性,还必须同时处理相对位置、相对取向和物理对称性。Point Transformer 将注意力机制引入点云学习,用局部邻域中的相对坐标调制特征聚合;Equiformer、ViSNet 等模型也在原子图上使用 attention-like 的权重,为局部消息传递中的节点相关性打分。它们说明注意力机制可以和三维几何结合,但多数实现仍然依赖邻居列表或截断半径,本质上是在局部图上做注意力。EFA 试图推进的正是这一点:在不显式枚举所有原子对的前提下,把全连接注意力的全局交互能力带回欧氏空间数据。
因此,EFA 并不是简单地把 Transformer 搬到原子图上。标准 self-attention 虽然天然具有全局交互能力,但如果显式计算所有原子对之间的相对位置,复杂度会回到 ;普通线性 attention 虽然可以避免二次复杂度,却缺少一种自然的方式来表达三维欧氏空间中的相对位移和旋转对称性。EFA 的由来正是在这两者之间寻找折中:它借鉴 RoPE 在 query-key 内积中编码相对位置的思想,将其推广为适用于三维坐标的 ERoPE,再通过球面积分和 linear attention-like 聚合,在接近线性的复杂度下表达全局几何相关。

2 前置知识
2.1 Message passing 与局部 cutoff
在机器学习力场中,message passing neural network(MPNN)通常把一个分子或材料结构表示成嵌入三维欧氏空间的图:每个节点对应一个原子,节点标签包含元素种类,边则由原子间距离是否落在给定截断半径内决定。换句话说,模型并不从一开始就看到一个全连接原子图,而是先根据局部邻居列表构造出一个稀疏图。
在第 层中,原子 的状态可以写成位置、元素和可学习特征的组合:
一次 message passing 更新可以分成三步。首先,模型从邻居 收集消息,并用对邻居置换不变的聚合操作合成原子 的总消息:
随后,更新函数把旧状态和聚合后的消息变成新的节点特征:
最后,readout 函数把各层节点状态映射为原子能量或其他局部贡献,再通过求和得到体系总性质。这种结构天然适合原子中心势场:局部邻域决定每个原子的表征,所有原子的贡献再组成整体能量。
局部 cutoff 是这类模型高效的根本原因。只要每个原子的邻居数在体系增大时近似保持常数,消息构造和更新的成本就可以接近随原子数线性增长。但这个设计也定义了模型的信息边界:一个原子只能直接接收截断半径内邻居的信息,更远的影响必须依赖多层消息传递逐步“跳转”过来;如果图在 cutoff 下不连通,某些远程信息甚至无法传播。
2.2 原子系统中的几何对称性
分子和材料不是普通图,而是嵌入三维空间的几何对象。模型如果显式满足这些几何对称性,就不必靠数据增强去反复学习同一个物理事实,也能把有限的 DFT 数据更集中地用于学习真正的化学差异。对势能这样的标量来说,整体平移和旋转不应改变能量;对力、偶极矩和中间向量特征来说,坐标系旋转后,输出也应以相同方式旋转。
最常用的对称性语言是欧氏群 ,它包含三维空间中的平移、旋转和反射。由于模型通常只依赖相对位置,平移不变性可以通过使用 这类相对坐标自然满足。剩下的关键是旋转和反射: 表示保持手性的三维旋转群, 则在 的基础上进一步包含反射。许多等变神经网络会用 或 的表示来组织内部特征。
若 或 作用在所有原子坐标上,内部特征应该按照相应的群表示 变换:
这里的 可以是平凡表示,也可以是更高阶的不可约表示。前者对应标量不变量,例如能量或只使用 invariant features 的模型;后者对应会随坐标系旋转而协同变换的向量、张量或更高阶特征。理解这一点很重要,因为 EFA 后面不仅要解决“远处原子能否相互看见”的问题,还要保证这种全局交互没有破坏原子系统应有的旋转不变性或等变性。
2.3 Attention 与 Linear Attention
在 Transformer 层中,输入可以看作一个特征序列 。每一层通常由两部分组成:一部分是逐点作用在每个 token 上的前馈网络,另一部分是 self-attention。前馈网络不负责序列之间的信息交换;真正让不同位置、不同节点互相通信的是 attention。
先看原始的 self-attention。给定输入特征 ,模型先通过三组可学习矩阵得到 query、key 和 value:
其中 。对第 个 query,attention 的一般形式是:先用某个相似度函数衡量 和所有 的相关性,再用归一化后的权重对所有 加权求和:
标准 Transformer 使用的是 softmax attention。它选择的相似度函数是指数核:
把这个相似度代入上面的通用 attention 公式,就得到熟悉的 softmax 形式:
也就是说,softmax attention 并不是 attention 的唯一形式,而是通用 attention 在选择指数相似度核后的一个特例。它的优点是每个 query 都能直接和所有 key 比较,缺点是必须显式形成 的相似度矩阵。构造 和用注意力矩阵乘 的主要复杂度都是 。
linear attention 的出发点是替换相似度函数。若存在一个特征映射 ,使相似度可以写成两个向量在特征空间中的内积:
那么通用 attention 的分子可以写成
分母也可以同样改写:
注意到,括号中的两项只依赖所有 key 和 value,不依赖具体的 query ,因此可以对整条序列只计算一次。写成矩阵形式,可以用如下等式表达:
也就是说,linear attention 不再显式构造 的注意力矩阵,而是先把所有 key-value 信息聚合成一个 的全局对象,再让每个 query 去读取它。当特征维度 远小于序列长度 时,复杂度可以从 降到近似 。EFA 后面要借用的正是这种“先全局聚合,再按 query 读取”的线性化思想。
2.4 RoPE
Rotary positional embedding(RoPE)的基本思想是:位置不以加性偏置的形式注入 token embedding,而是通过对 query 和 key 的特征通道施加位置依赖的旋转变换,使位置信息进入后续的内积计算。形式化地,考虑序列位置 上的一条 query 或 key 向量 。为便于定义旋转操作,假设 为偶数,并将其通道划分为 个二维子空间:
其中第 个二维特征对定义为 ,即原始特征向量中第 与第 个通道张成的二维子空间。将该二维子空间同构为复平面,可定义复数表示
在这一表示下,对位置 施加 RoPE 等价于乘以一个位置相关的单位复数:
等价地,它是在每个二维子空间中应用一个旋转矩阵:
这里的 是第 个频率,不同特征通道可以对应不同的旋转速度。RoPE 的核心性质出现在 query 和 key 做内积时。若位置 的 query 和位置 的 key 分别乘上相位因子 与 ,那么它们的复数内积会出现相位差:
因此,RoPE 并不是让 attention 记住“第 个 token 的绝对位置”,而是让 query-key 相似度天然包含相对位移 。这正是 ERoPE 借鉴的思想:如果一维序列中可以通过旋转相位让内积产生相对位置,那么三维欧氏空间中也可以尝试用类似的相位结构,让原子坐标的相对位移出现在 query-key 内积里。
3 研究问题与方法设计
3.1 局部消息传递模型的长程表达瓶颈
局部 MPNN 的基本假设是,原子 的表示可以通过其截断半径内的邻居逐层更新得到。这个假设在短程化学环境中非常有效,因为共价键、局部配位结构和近邻排斥等效应主要由有限范围内的原子决定。然而,许多分子和材料性质并不能完全由局部环境刻画。静电作用、色散作用、分子间非共价相互作用、电荷转移以及电子离域效应都可能跨越局部 cutoff,并对能量、力和动力学路径产生可观影响。
从图传播的角度看,增加 MPNN 层数确实可以扩大感受野。若每层的截断半径为 ,经过 层后,信息理论上可以沿着邻接图传播到更远的节点。但这种传播并不等价于直接建模远程相互作用。首先,远处节点的信息需要经过多个中间节点中继,传递路径越长,表示越容易被局部聚合操作平滑或压缩。其次,有效感受野依赖于 cutoff 图的连通性;如果两个区域在局部邻接图中没有可达路径,即使它们在物理上存在长程作用,模型也无法通过 message passing 交换信息。最后,单纯增加层数会提高计算成本和优化难度,并可能引入过平滑等图神经网络常见问题。
因此,文章所讨论的核心困难不是“局部模型完全不能表示远程效应”,而是:在保持机器学习力场所需的近线性复杂度和几何对称性的同时,如何为每个原子构造能够直接访问全局结构的表示。EFA 的目标正是补足局部 message passing 在全局相关建模上的结构性不足,而不是取代其对短程化学环境的建模能力。
3.2 全连接注意力的二次复杂度障碍
从表征能力上看,self-attention 似乎天然适合处理长程相关,因为它允许每个节点在一次更新中直接访问所有其他节点。若将这一机制直接移植到原子系统,一个自然的想法是:对任意原子对 ,以 query、key 的相似度衡量它们之间的信息耦合,再用该权重对 value 进行加权聚合。为了使这一聚合反映真实几何,attention kernel 还必须显式依赖原子间距离、相对位移或更一般的相对取向信息。
问题在于,一旦这种几何依赖是以 pairwise 的方式引入,模型就必须对所有原子对构造并评估相应的相似度项。对于包含 个原子的体系,这意味着显式形成一个 的相互作用结构;无论是距离矩阵、位移矩阵,还是经 softmax 归一化后的注意力矩阵,其时间和存储代价都不可避免地呈二次增长。对自然语言任务而言,这一代价已经足以成为长序列建模的瓶颈;对机器学习力场而言,问题更为尖锐,因为实际应用经常面向数万乃至数十万原子的体系。换言之,标准全连接 attention 的障碍并不在于缺乏表达能力,而在于它以一种与大规模原子模拟不相容的代价换取了这种表达能力。
因此,若希望将 attention 用于机器学习力场,问题就不再是“attention 是否能够表达全局相互作用”,而是“是否存在一种不显式枚举全部原子对、却仍保留全局耦合能力的 attention 形式”。这正是作者转向线性 attention 思路的直接动因。
3.3 线性注意力中的欧氏几何约束
线性 attention 之所以可行,本质上依赖于一个可分解性条件:attention kernel 必须能够写成 query 与 key 在某个特征空间中的内积,从而把原本依赖 的 pairwise 计算,改写为“先对全部 key-value 做一次全局聚合,再由每个 query 分别读取”的形式。对于仅依赖特征相似性的序列数据,这一改写是自然的,因为 kernel 的自变量只有 和 ;但对欧氏空间中的原子体系而言,真正重要的量并不只是特征相似度,而是相对几何关系。
更具体地说,原子间相互作用通常依赖于相对位移 ,甚至进一步依赖于由多个原子共同决定的取向结构。若要在 attention 机制中忠实编码这些几何量,一个直接方案是令相似度核显式依赖 或 。然而,一旦这样做,kernel 就不再显然具有线性 attention 所要求的可分解形式;因为 是由两个位置共同决定的 pairwise 变量,而不是可以分别附着在第 个 query 与第 个 key 上的独立项。换言之,线性 attention 所要求的“可分解性”,与欧氏几何天然呈现的“相对性”之间存在直接张力。
除此之外,欧氏空间数据还受到严格的物理对称性约束。即便能够构造某种线性化的几何编码,如果它不能在平移、旋转乃至反射下保持正确的不变性或等变性,那么这种机制对于机器学习力场仍然是不可接受的。因此,真正的问题是:线性 attention 在欧氏空间中的困难,并不只是“如何把复杂度从二次降到线性”,而是“如何在保持线性复杂度的同时,使几何信息的编码仍然尊重物理对称性”。
3.4 ERoPE 与 EFA 的设计原则
作者的设计原则可以概括为三点。第一,几何信息不应再以显式构造全部 pairwise 距离或位移的方式进入 attention,而应当被编码进每个原子的局部表示中,使 query-key 内积在计算时自动恢复相对几何关系。第二,这种编码必须与 attention 的线性化形式兼容,也就是说,它应当允许全局聚合步骤在不显式形成 矩阵的前提下完成。第三,最终机制必须满足原子系统所要求的平移不变性以及旋转不变性或等变性。
ERoPE 正是在这些约束下提出的。它借鉴 RoPE 的核心思想:对 query 和 key 施加位置相关的相位,而不是将位置作为外加特征直接拼接到表示中。区别在于,RoPE 处理的是一维序列位置,而 ERoPE 面向的是三维坐标。作者的关键观察是,只要相位依赖于位置在某个方向上的投影,那么两个编码后的向量做内积时,就会自动出现相对位移项;这样一来,几何关系并不是通过外部构造的 pairwise 特征注入的,而是在内积结构中自然生成的。随后,再通过对单位球的积分或与球谐函数耦合,可以分别恢复旋转不变或旋转等变的表达形式。
EFA 则是在线性 attention 框架中对这一编码方式的系统化实现。它保留了“先对全部 key-value 做全局聚合,再由每个 query 读取”的线性复杂度结构,同时利用 ERoPE 使这一聚合对欧氏几何敏感。于是,EFA 的方法设计可以被理解为对两种需求的同时满足:一方面,它继承了 attention 的全局交互能力;另一方面,它避免了标准全连接 attention 对所有原子对显式建模所带来的二次复杂度。
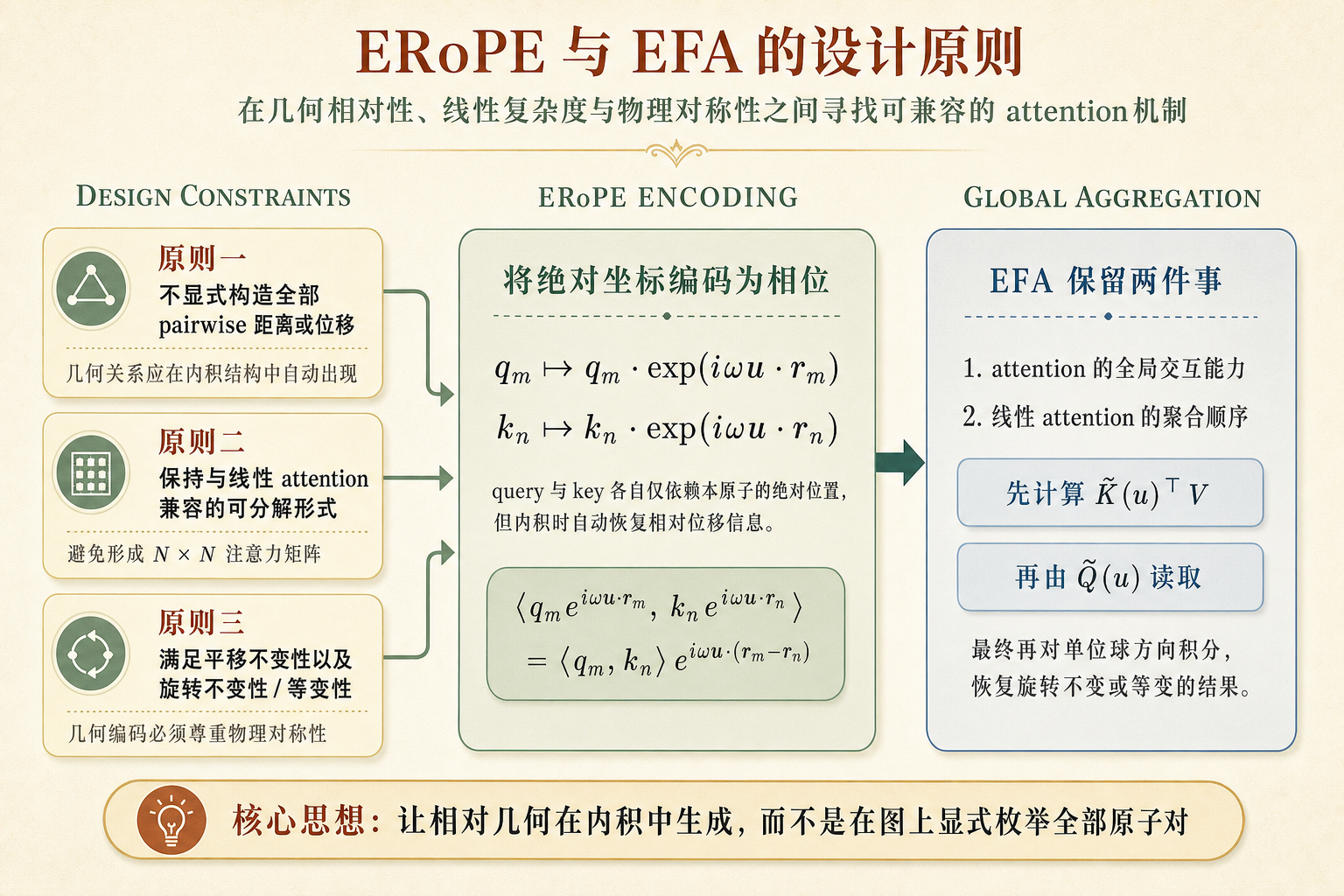
4 ERoPE 与 EFA 的数学构造
4.1 三维欧氏空间中的相位编码
ERoPE 的基本思想是:不显式构造任意原子对之间的几何特征,而是先把每个原子的绝对坐标编码进 query 和 key 的相位中,使相对几何在内积计算时自动出现。设 为输入特征, 为对应位置, 为单位球面上的方向向量, 为频率参数,则 ERoPE 定义为
这里的 是位置 在方向 上的投影,因此 ERoPE 可以理解为沿方向 的平面波相位编码。与一维 RoPE 相同,ERoPE 的关键并不在于为单个原子构造某种独立解释的绝对位置表示,而在于它如何重写 query 与 key 的内积。
设第 个原子的 query 为 ,第 个原子的 key 为 ,对应位置分别为 与 。将 ERoPE 分别作用于二者,则有
因此,虽然 ERoPE 分别作用在每个原子的绝对坐标上,真正进入 attention-like 相似度的是相对位移 。更准确地说,进入相位的是 在方向 上的投影 。这一步非常关键,因为它表明几何关系并非通过显式构造全部 pairwise 位移矩阵引入,而是在 query-key 内积中由相位差自然生成。
4.2 单位球积分与旋转不变性
式 (15) 仍然包含一个任意选择的方向 。这意味着编码结果虽然已经满足平移不变性,却尚未满足旋转不变性:如果整体旋转所有原子, 会随之改变,而固定的 会引入一个外在参考系。为消除这一参考系,可以对单位球上的全部方向进行平均:
这个结果可以通过显式积分直接验证。取坐标系使 沿极轴方向,则有 ,从而
令 ,则上式化为
即式 (16) 的结果。于是,原先依赖方向投影 的相位因子,被化为仅依赖距离 的径向函数。球面积分消除了任意参考方向,从而把 ERoPE 诱导出的几何依赖变成了严格的旋转不变量。
如果对不同特征通道使用不同的频率 ,那么最终得到的并不是单一的 核,而是一组不同频率径向函数的线性组合。这一点解释了为什么 ERoPE 虽然形式简单,却能够表达比单一径向滤波器更丰富的距离依赖关系。
4.3 球谐函数与等变扩展
仅有式 (16) 还不足以处理等变特征,因为它只产生标量不变量。为了从旋转不变扩展到旋转等变,可以在球面积分中进一步引入球谐基 。这样得到的输出不仅依赖原子间距离,还可以携带关于方向的张量化信息。需要强调的是,这里的方向信息并不是通过一个显式的方向化 attention score 引入的;EFA 的核心 query-key 兼容性仍然来自标量型收缩,而方向依赖主要体现在球谐基所张成的输出结构中。
更具体地说,若将式 (15) 中的平面波相位与球谐函数共同积分,则对每个角动量阶数 都会得到一个“径向部分与角向部分分离”的结构:
其中 是阶数为 的 spherical Bessel function, 为单位方向。这个公式说明:式 (16) 中仅给出标量不变量的 核,在引入球谐基之后会自然推广为“径向函数 角向基函数”的分离形式。径向依赖由 承担,方向依赖则由 承担。
若再考虑多个频率 、多个通道以及前后线性映射的组合,那么这些 的线性组合就构成了最终的向量值径向核。我们将这个以 为变量的线性组合记为 ,代表由前述 ERoPE 相位项经过球面积分、频率混合与通道投影之后所诱导出来的径向部分。于是,从结构上看,EFA 与常见的 等变卷积出现了直接联系,其输出可以写成
其中 为向量值径向函数,具体指由 及其跨频率、跨通道线性组合构成的径向核; 为单位方向, 表示哈达玛积, 表示张量积。这个表达式说明:在积分完成之后,EFA 的输出形式与等变卷积极为相似,只是其核函数并非由显式构造的局部邻域卷积给出,而是由相位编码、球面积分和线性 attention 聚合共同诱导出来。
因此,严格地说,EFA 在这里实现的并不是“具有显式方向张量权重的注意力机制”,而是一种以标量兼容性为核心、并借助球谐展开恢复方向等变输出的全局积分算子。这个区分并不否定其等变性,但有助于更准确地理解其表达机制与潜在边界。
4.4 Euclidean fast attention 的基本形式
在完成上述几何编码之后,可以将其嵌入到线性 attention 框架中。先从未归一化的线性 attention 原型出发:
其中 是任意特征映射。与标准 attention 相比,这里省略了归一化分母;在机器学习力场的语境下,这种写法是自然的,因为许多长程作用本身具有加性结构。接下来,对每个方向 定义
又由于式 (14) 中的 ERoPE 是通过复指数相位定义的,因此在后续的收缩中需要对 key 分支取复共轭;这里的 表示逐元素复共轭。于是,在固定方向 上的几何敏感线性聚合可以写为
最后再对全部方向积分,就得到 invariant EFA:
如果进一步记
则式 (21) 可以改写为
从而更清楚地显示出其线性 attention 结构:先对全部 key-value 做一次全局聚合,再由第 个 query 读取聚合结果,只不过这里的聚合是几何敏感的。
若进一步引入球谐函数,就得到等变形式:
式 (21) 与式 (22) 正是前几小节结论的汇合点:ERoPE 负责把绝对坐标转化为会在内积中生成相对位移的相位结构,球面积分负责恢复旋转不变性,球谐函数负责扩展到等变情形,而线性 attention 的聚合顺序则保证了整个机制不必显式构造 的注意力矩阵。也正因为如此,EFA 可以被理解为一种真正面向欧氏空间数据的 linear-scaling attention,而不是把现有 attention 机制机械地移植到原子图上。
5 算法实现与系统复杂度
5.1 EFA block 的计算流程
以下采用最一般的实现情形,即输入允许为等变特征。设第 层进入 EFA 的原子表示为 ,其中每个原子特征可写为
这里 是 parity axis 的大小, 是 feature axis 的维数, 是最高角动量阶数, 标记 parity。若 ,特征仅包含 tensors;若 ,偶宇称与奇宇称切片分别存放在 parity axis 的不同位置。对固定的 ,矩阵 的行索引 枚举该 irrep 的 个分量,列索引 枚举可学习通道。后文插图仅用于说明线性投影的轴向关系,因此采用 的简化情形;一般公式仍保持任意 的写法。
EFA block 的第一步是沿 feature axis 生成 query、key 和 value。对每个 切片,引入彼此独立的线性映射
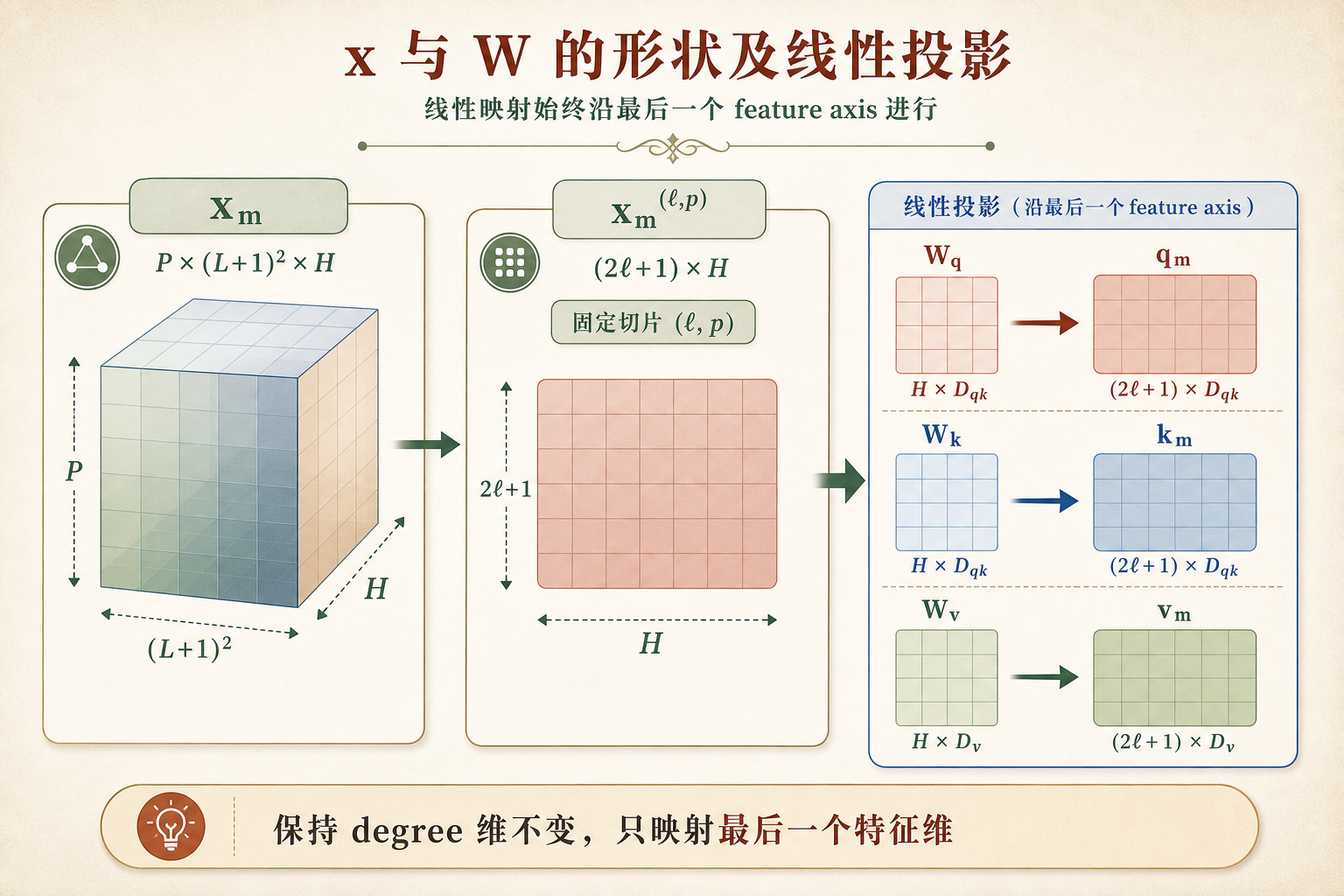
其中
因此
式 (23) 中的矩阵乘法只沿 feature axis 进行。更明确地说,若将 作为 query/key 的输出通道索引、 作为 value 的输出通道索引,则
其中重复指标 服从爱因斯坦求和约定。由此可见,degree 轴与 parity 轴在这一阶段仅充当批维;真正发生线性投影的是最后一个 feature 轴。后续收缩要求 query 与 key 具有完全相同的 组织,而 value 则可以使用不同的 。
第二步是将原子坐标编码进 query 和 key。虽然前文以复指数记号定义了 ERoPE,但在实际实现中作者采用等价的实值形式:把相邻两个 feature 通道视为一个二维平面,并在该平面内施加位置依赖的旋转。对任意 ,若 ,则
这与前文的复数相位写法完全等价,但更适合张量实现。若 为奇数,则先在 feature 轴末尾补零到偶数维。允许不同二维通道对使用不同频率 的原因也在这里体现出来:积分之后,不同通道会对应不同的 或更一般的 型径向依赖,从而提升径向表达能力。
随后,对 query 和 key 先施加保持等变性的特征映射 ,再逐行施加 ERoPE。更准确地说,ERoPE 只作用于每一行对应的 维 feature 向量,而不作用于 所标记的 irrep 分量:
在论文的实验中, 取恒等映射或 gated GELU,并且同样逐元素作用于 feature axis。把所有原子的各个 切片按既定顺序拼接后,可得
只有 query 和 key 依赖方向 ,因为只有它们经过了 ERoPE 编码;value 保持原有的等变表示,不额外引入相位。换言之,几何信息被注入的是 query-key 兼容性结构,而不是 value 自身。
接下来考虑固定方向 时的全局聚合。为了避免符号歧义,引入两个复合指标
并将 、 与 分别视为数组
则 key-value 聚合与 query 读取可写为
这里重复指标 与 都按照爱因斯坦求和约定求和。第一步先在原子索引 上聚合所有 key-value 对,得到与具体 query 无关的全局张量 ;第二步再由每个 query 切片从左侧读取该张量。若恢复结构化轴,便有
因此,式 (26) 的精确含义是一系列张量收缩,而不是普通的二维矩阵乘法。也正因为如此,计算过程中始终不需要显式构造 的 pairwise attention matrix。
最后一步是对单位球积分进行数值离散。论文采用 Lebedev 求积,其基本形式为
Lebedev 求积的关键性质在于:它对一定阶数以下的球面多项式可精确积分;例如, 的最小网格已经能够无误差地积分总次数不超过 的多项式。由于 EFA 的连续形式本身带有前因子 ,将式 (27) 代入后便得到离散化的 EFA 更新
其中 在实现中被写成带有若干 singleton axes 的张量,以便与 广播并执行张量积。当 时,,式 (28) 退化为 invariant EFA;当 时,输出显式保留方向等变信息。
综上,EFA block 的计算顺序可以概括为:先按 切片沿 feature axis 生成 query、key 和 value;再对 query 与 key 施加 和 ERoPE;随后对每个 Lebedev 方向 先形成一次与 query 无关的全局张量 ,再由全部 query 读取得到 ;最后将其与球谐张量 耦合,并依照权重 在球面上求和。由此得到第 个原子的非局域更新 。在完整的 MP+EFA 网络中,该非局域更新随后通过残差路径送入等变 MLP,并与局部 message passing 分支并行组合,从而在同一层内同时编码短程与长程信息。
5.2 复杂度分析:从 O(N^2) 到 O(NG)
EFA 的线性标度并不是来自对 pairwise 相互作用的近似截断,而是来自张量收缩顺序的重排。若直接使用几何化的全连接 attention,则必须显式计算所有 原子对的兼容性项,因此时间与存储都会随 增长。EFA 的关键在于:对固定方向 ,它并不先构造一个 的 attention matrix,而是先形成与具体 query 无关的全局张量 ,再由全部 query 读取。
沿用上一节的复合指标记号,记
则对单个方向 ,式 (26) 的两步计算分别为:先形成
这一步需要对 求和,因此其代价与 成正比;随后再计算
其代价同样与 成正比。因而,对固定方向 ,EFA 的主要计算量可写为
如果把 和 视为由模型架构决定的常数,而只考察系统规模 的增长,那么式 (29) 就是线性于 的。再考虑球面积分的离散化,需要对 个 Lebedev 网格方向 各执行一次相同的计算,因此整个 EFA block 的总代价为
这正是论文中所强调的 linear-scaling 结论。需要注意的是,式 (30) 省略了与特征维度有关的常数因子;从实现角度看,真正被压缩掉的是对 pairwise 兼容性张量的显式构造,而不是所有与特征维度有关的计算。
存储复杂度的改善同样来自这一点。对固定方向 ,临时量中最关键的是
以及与原子数线性相关的 、 与 。因此,EFA 在实现上避免了标准 attention 中最昂贵的 存储瓶颈。就这一点而言,它更接近“先构造全局统计量、再由每个原子读取”的核方法,而不是显式 pairwise attention。
不过,式 (30) 还隐含了一个重要前提:随着系统规模增大,网格点数 必须能够保持近似常数。只有在这一前提下,EFA 才严格地对 线性扩展。若为了维持同等的数值旋转等变精度而必须增大 ,则实际成本会变为 。因此,EFA 相比二次复杂度方法的计算优势,本质上建立在两个条件之上:一是 ,二是随着系统尺寸增加,不需要同步显著提高球面积分的分辨率。
5.3 Lebedev 求积与数值精度
EFA 的旋转不变性与旋转等变性并不是通过解析积分在程序中精确实现的,而是依赖 Lebedev 求积对单位球面积分的数值近似。因此, 的选择不仅影响计算成本,也直接决定了最终的数值对称性精度。这里的核心问题在于:给定一个有限网格,哪些频率和距离尺度仍然可以被足够精确地积分?
困难来自于 EFA 的被积函数并不是单纯的低阶球谐函数。对固定频率 与相对位移 ,ERoPE 引入的是 与 这类振荡项。一个自然的分析办法是把
视为展开变量,并考察相应三角函数在 附近的 Taylor 展开。 越大,为了逼近这些振荡项所需的展开阶数就越高;再叠加球谐函数 的最高阶数 ,就得到一个“有效总次数”的估计。对于给定的 Lebedev 网格大小 ,它只能对某一范围内的有效总次数保持足够高的精度,这个范围便被论文概括为某个最大允许参数 。
于是,对所有实际出现的频率与距离组合,都需要满足
若再记 为数据集中预期出现的最大原子间距,则一个自然的频率截断准则是
式 (31) 的含义是:在给定网格大小 的前提下,通过选择不超过 的频率集合 ,可以把数值积分误差控制在预设阈值以内。实际使用时,可以先从数据中估计最大分离距离 ,再据此反推允许的最大频率范围;作者在实验中通常还会把这个距离向上取整到最近的 倍数,以留出一定余量。
接下来的问题是: 如何确定?这里没有可直接套用的封闭解析式,而是需要用已知的解析积分结果做数值标定。具体来说,可将数值 Lebedev 积分与解析球面积分进行比较,并把
作为允许的最大绝对偏差;满足这一阈值的最大 即被定义为该网格对应的 。这个阈值大致对应单精度浮点运算的数值精度。作者给出的经验标定结果表明: 时 , 时 , 时 , 时 ,而 时可以达到 。这提供了一个直接的工程规则:若已知数据中的最大距离尺度与所需频率范围,就可以反向选择足够密的 Lebedev 网格。
数值实验还提供了一个更直观的视角。将数值 EFA 的输出与前几个解析球 Bessel 函数 进行比较,可以看到:只要网格足够密,二者在相当大的距离区间内几乎重合;偏差首先出现在较大的
区域,并且随着球谐阶数 的升高会略微提前出现。这说明误差的主导控制变量并不是系统中原子的总数,而是频率与距离尺度的乘积 。换言之,只要所需的频率范围不过高,EFA 即便使用相对较小的 也能很好地描述长程、缓变的相互作用;反过来,如果希望在很大的 上同时保留较高频率成分,就必须显著加密 Lebedev 网格。
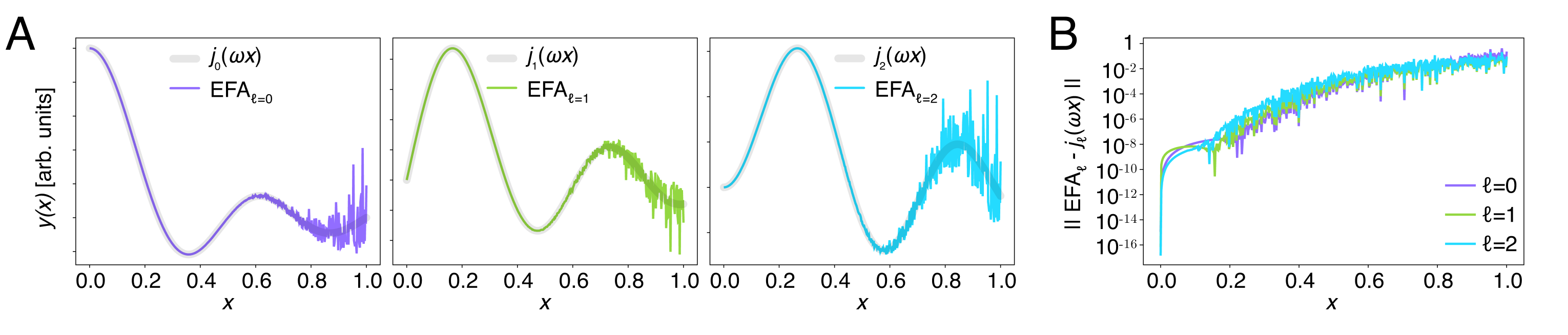
这也解释了论文最后的实践建议。对于很多长程相互作用任务,较低的 已经足够,因此完全没有必要采用过密的球面网格。并且, 的变化只影响数值积分精度,并不改变网络已经学到的相互作用形式;因此,作者特别指出, 甚至可以在模型训练完成后再做基准测试和调节,以寻找效率与精度之间更合适的折中。
5.4 EFA 与局部 MPNN 的互补关系
EFA 在网络中的角色并不是替代 message passing,而是作为一个与局部消息传递并行的非局域分支。为了避免前文符号中的层编号歧义,这里统一把一整个 hybrid update block 记为:输入原子表示为 ,输出为 。在这一层中,局部分支与非局部分支共享同一组输入特征,但分别编码不同尺度的几何相关。
先看局部分支。对原子 ,最一般的 message passing 写法是先从邻域 中收集局部消息
再通过一个保持等变性的点态非线性映射更新单原子表示:
式 (32) 并不预设具体的 MPNN 结构;无论局部核函数是基于距离基展开、球谐函数张量积,还是更一般的等变连续卷积,都可以抽象为 。唯一关键的限制在于:它只在局部邻域 内聚合,因此其感受野由 cutoff 与层数共同决定。
非局部分支则完全不同。它不再沿图边逐跳传播信息,而是直接对整组原子表示施加 EFA:
这里的差别不在于输出类型,而在于聚合路径: 只由邻域原子贡献,而 在一次更新中就可以访问所有原子。由于局部分支和 EFA 分支都从同一输入 出发,并且都输出到同一个等变特征空间,因此它们可以在层末端做直接的加法融合:
式 (36) 才是这篇工作中“MPNN 与 EFA 有机结合”的核心。它并不是先用 EFA 替换局部卷积,再由网络重新学习短程结构;相反,它把同一层拆成两个功能互补的算子:一个专门处理局部、强烈、快速变化的短程相互作用,另一个专门处理跨越 cutoff 的全局相关。二者共享表示空间、共享残差入口,但承担的几何任务不同。
若改写成算子形式,则这一层可以概括为
其中 表示由局部消息传递与局部等变 MLP 组成的映射, 则表示由 EFA 与非局域等变 MLP 组成的映射。式 (37) 明确表明:EFA 不是替换局部模型的主干,而是作为与之并行的补充分支接入同一层更新。

这种设计之所以自然,至少有三个原因。第一,局部分支和非局部分支都保持 对称性,因此它们的输出可以无歧义地相加;若二者输出的表示类型不同,式 (36) 本身就不成立。第二,短程相互作用往往具有更高的空间频率,使用局部核函数更经济也更稳定;而长程相互作用通常变化更平缓,更适合由 EFA 的全局积分结构来表达。第三,EFA 分支使用的是加性、非归一化的 attention-like 聚合,这与原子能量和相互作用的 size-extensive 性质是相容的;因此它作为一个附加的非局域修正项,和局部 message passing 在物理上是协调的。
如果把整个网络看成由若干个这种 hybrid block 串联而成,那么每一层都同时完成两件事:局部分支扩展并细化 cutoff 内的化学环境表示,非局部分支补入全局几何相关;经过多层叠加之后,最终读出头只需从最后一层的 invariant 通道中预测每原子能量并求和即可。换言之,EFA 并没有改变 MPNN 的整体监督目标和读出方式,它改变的是每一层内部的信息路由结构。
5.5 周期性体系中的参考方向选择
前面关于 EFA 的讨论默认处于最“干净”的情形:体系是孤立的、非周期的,并且空间中不存在任何外加参考方向。在这种情况下,方向向量 只是一个辅助变量,任何固定选择都会人为引入坐标系依赖。因此,必须对整个单位球做平均,才能把这种任意性消去。换言之,对于孤立体系,我们要求的是
或者在等变情形下满足相应的协变变换律。这里的关键点是:旋转只作用于原子坐标本身,因为体系中没有第二组几何对象来充当参考系。
周期性体系则根本不同。除原子坐标 之外,晶体还带有晶格向量
它们本身就定义了一个优先参考框架。此时物理上合理的对称性不再是“在固定晶胞内任意旋转所有原子”,而是“把原子和晶格一起刚性旋转”。更精确地说,我们希望满足的是
而一般并不要求
这就是周期体系与非周期体系最本质的区别:在孤立分子中,方向参考系必须被“积分掉”;而在晶体中,晶格本身就是物理上存在的参考系,因此没有必要再对整个单位球做平均。
基于这一点,可以把前面通过球面积分实现的 symmetrization,改写成沿若干个晶格导出方向的有限求和。最简单的标量形式是直接选取三条晶格方向 ,并写成
如果只关心 invariant 输出,上式已经足够说明机制:原先连续的球面积分被三个由晶格选定的方向取代。这样做的效果是,EFA 的参考方向不再来自任意选取的球面采样,而是来自晶体真实的几何结构。只要晶格与原子一起旋转,式 (38) 的结果就保持不变。
从实现角度看,这种替换带来两点直接变化。第一,不再需要 Lebedev 求积,因此前面关于网格点数 、 和数值积分精度的讨论在这里不再是主导问题;这也是作者在周期体系实验中不再单独给出 的原因。第二,旋转对称性的要求变弱了:我们不再追求“对任意球面方向平均后的严格各向同性”,而是接受由晶格参考系引入的各向异性,因为这种各向异性本来就是周期材料的一部分。
不过,式 (38) 也不是唯一选择。若数据集中包含多个不同尺度或不同形状的晶胞,直接使用未经处理的晶格向量会把晶胞尺度同时编码进方向与长度中。为了让不同晶胞之间的表示更可比,可以改用归一化后的晶格向量,或者改用倒格矢。这样做的目的不是恢复各向同性,而是让“参考方向”更多承担方向编码的职责,而把尺度信息留给其他通道去表达。
因此,本节真正要强调的不是某个具体公式本身,而是对称性要求的改变:对于孤立体系,EFA 需要通过球面积分消除任意参考方向;对于周期体系,参考方向恰恰是已知且物理上有意义的晶格结构,于是最合理的做法不是把它平均掉,而是显式地把它纳入 EFA 的定义中。这一转变也使 EFA 与 Ewald 类长程方法之间的联系变得更加直观,因为二者都在利用周期结构天然给出的频域或方向参考框架。
6 实验结果与物理解释
6.1 理想化体系中的几何表达能力
作者先用一组高度可控的理想化任务隔离几何表达能力本身,而不让真实化学体系的复杂统计分布掩盖结论。实验包括三部分:局部邻域可区分性、几何 Weisfeiler-Leman 图可区分性,以及一个同时依赖距离与取向的二维各向异性势能面。这里的目标很明确:先回答 EFA 能否表达“全局几何”和“方向信息”,再去讨论真实数据上的精度收益。
在配置上,作者分别控制两类能力参数:对 EFA 而言,核心变量是球谐最高阶数 ;对 MPNN 而言,核心变量是消息传递层数 与局部 cutoff。比较方式也很直接:若任务只靠局部距离即可解决,那么浅层 MP 应当足够;若任务依赖全局结构或方向取向,那么 EFA 的一次全局更新应当更有优势。
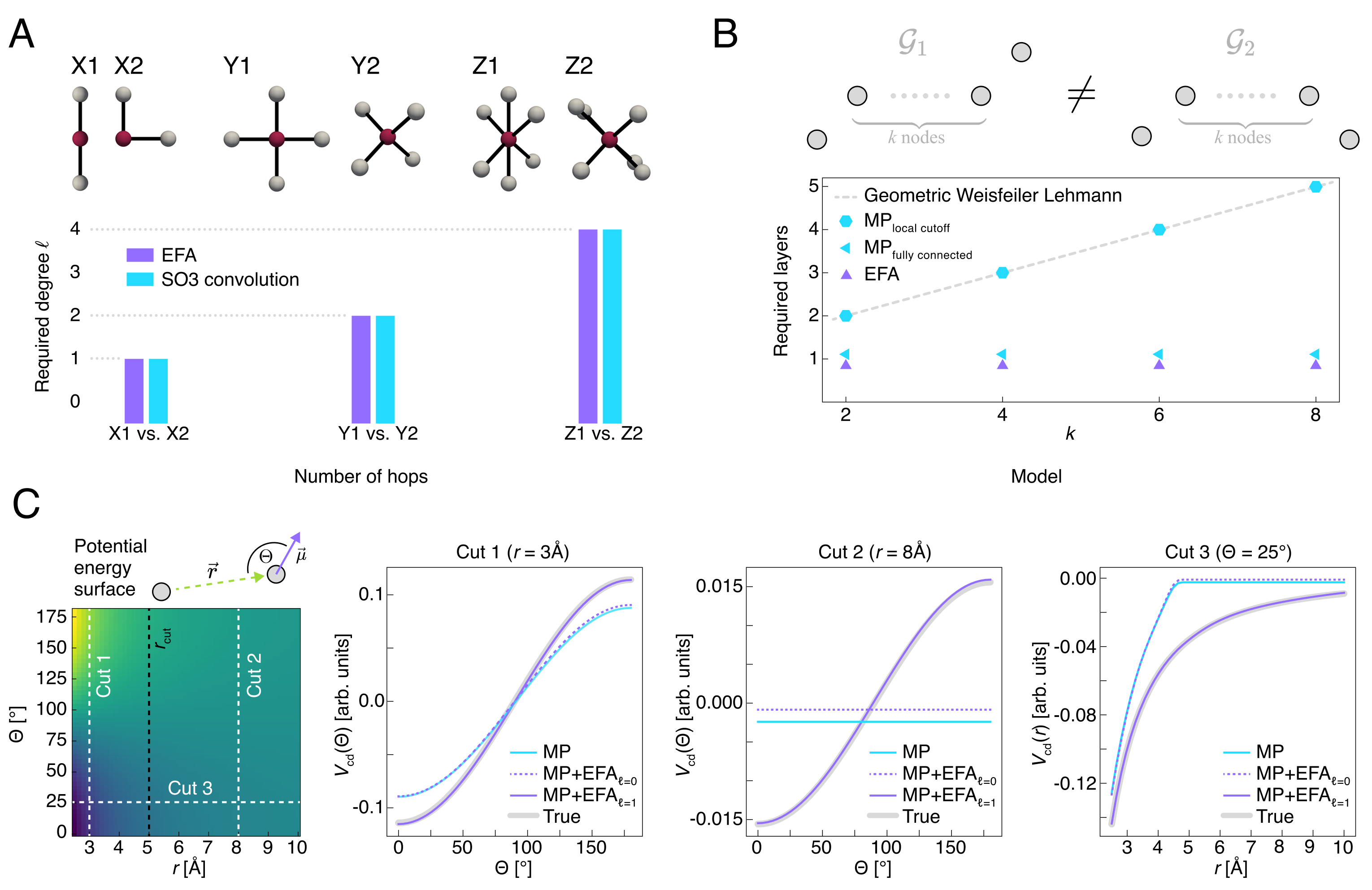
结果可以概括为三点。第一,EFA 与 SO(3) convolution 在“提高 以提升几何可区分性”这一点上表现出相同趋势。第二,在 k-chain 图任务中,标准 MP 需要随链长增加层数,而 EFA 在单次更新中即可区分非同构图。第三,在各向异性相互作用上,只有包含方向信息的 MP+EFA 才能在 cutoff 之外保持正确势能形状。这个理想化部分的意义在于,它把后续所有真实体系结果都压缩成一句话:EFA 的优势首先来自几何表达能力,而不是训练技巧。
6.2 NaCl-like 系统中的长程相互作用与线性扩展
NaCl-like 系统是全文最直接的“长程相互作用 + 标度”检验。作者构造了随直径 增大的球形离子簇,其中带负电的 Cl 与带正电的 Na 之间通过 screened Coulomb 势相互作用。这个设置既足够简单,便于控制系统尺寸,又已经包含了局部 cutoff 模型最容易失真的长程尾部。
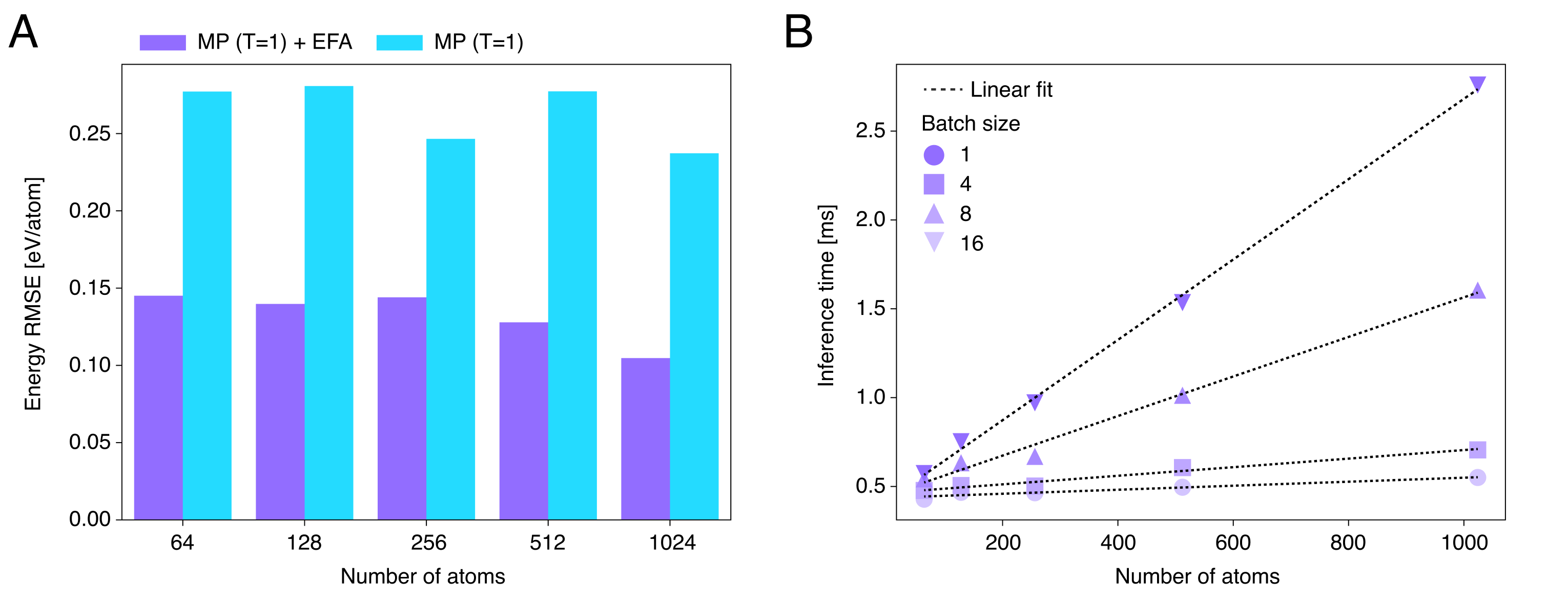
在主文实验中,作者比较的是单层 MP 与单层 MP+EFA,并把 MP 的 cutoff 固定为 ;随后再把 MP 的层数增加到足以让“有效 cutoff”覆盖整个系统,以检验“多跳传播是否真的等价于全局交互”。补充实验还进一步测试了一个更强的外推场景:只在两粒子 NaCl-like 系统上训练最小 EFA 变体,再把它直接应用到 量级原子数的更大体系上。
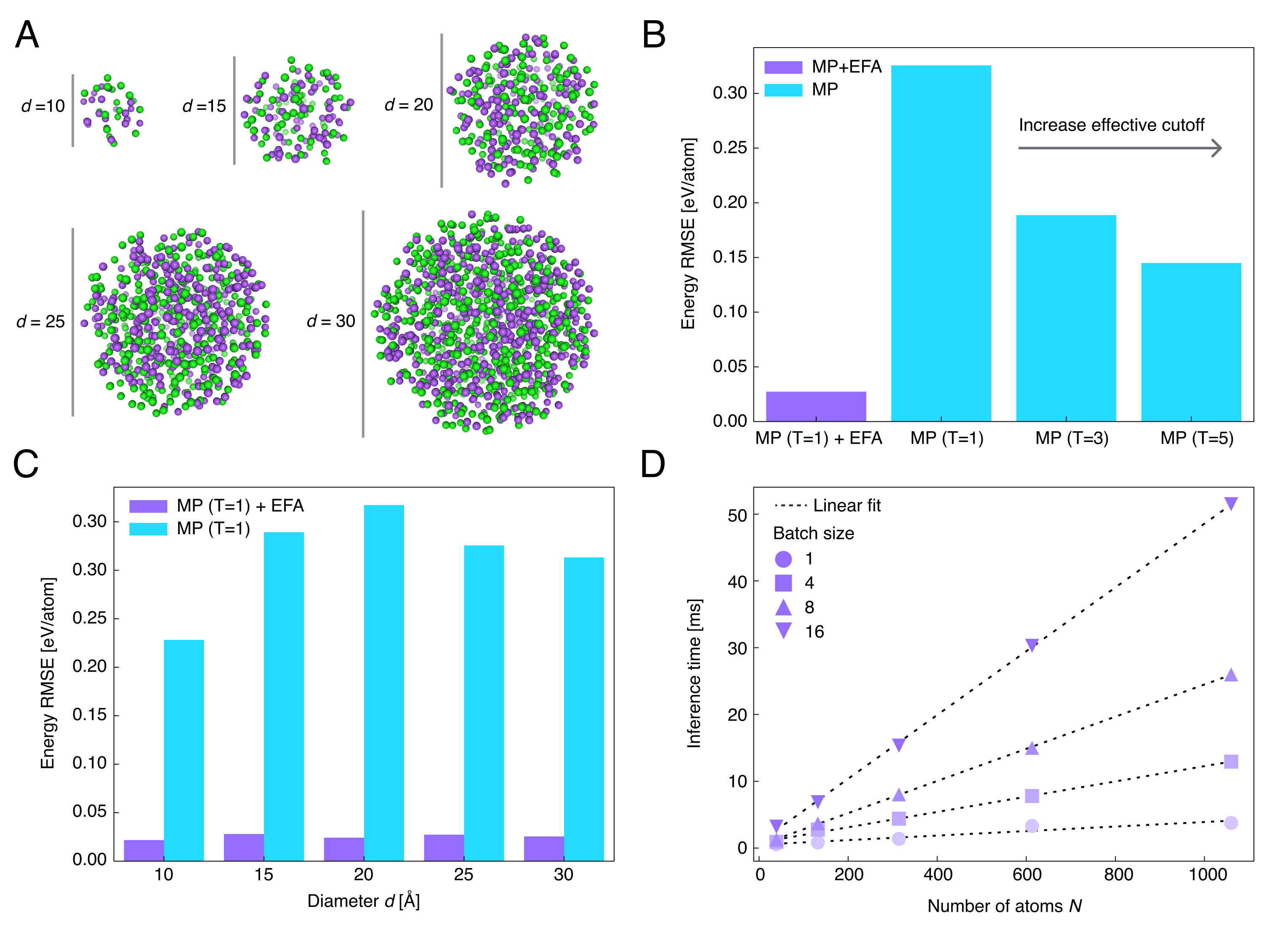
结果同样很集中。加入 EFA 后,单层模型在所有直径上都显著优于纯 MP;并且推理时间随原子数近似线性增长。更重要的是,即使把 MP 的层数增加到让有效 cutoff 覆盖整个系统,性能仍然不如带 EFA 的浅层模型。作者据此提出一个很关键的判断:MP 中不同局部邻域之间的“mean-field”式多跳传播,并不能完整替代直接的全局几何耦合。对于周期性 NaCl bulk,作者还报告了相同趋势:在使用晶格参考方向的周期版 EFA 后,能量误差和与真值的相关性仍优于局部 MP。
6.3 非局域电荷转移、SN2 反应与非共价二聚体
进入真实数据后,作者先用一个非局域电荷转移基准测试 EFA 的通用性。这个基准同时包含分子与材料体系,也同时覆盖有无 PBC 的场景。对比对象除了本工作的 MP 与 MP+EFA 外,还包括 2G-BPNN、4G-HDNNP 与 SpookyNet 等已有非局域方法。结论很干脆:MP+EFA 在八个能量/力指标中拿到了七项最优,说明它并不是只在某一类 toy task 上有效,而是能跨越分子和材料两类体系稳定发挥作用。
SN2 反应与二聚体实验则分别对应两类典型长程问题。SN2 部分研究的是 X + HC—Y X—CH + Y 这一类反应坐标较长、远程相互作用显著的体系。作者使用局部 cutoff 为 的 MPNN 作为基线,并比较三种方案:纯 MP、增大到 的 MP,以及加入 EFA 的 MP。二聚体部分则使用 DES370K 基准,要求模型同时泛化不同分子结构与不同长程作用形式,如静电、诱导和色散。
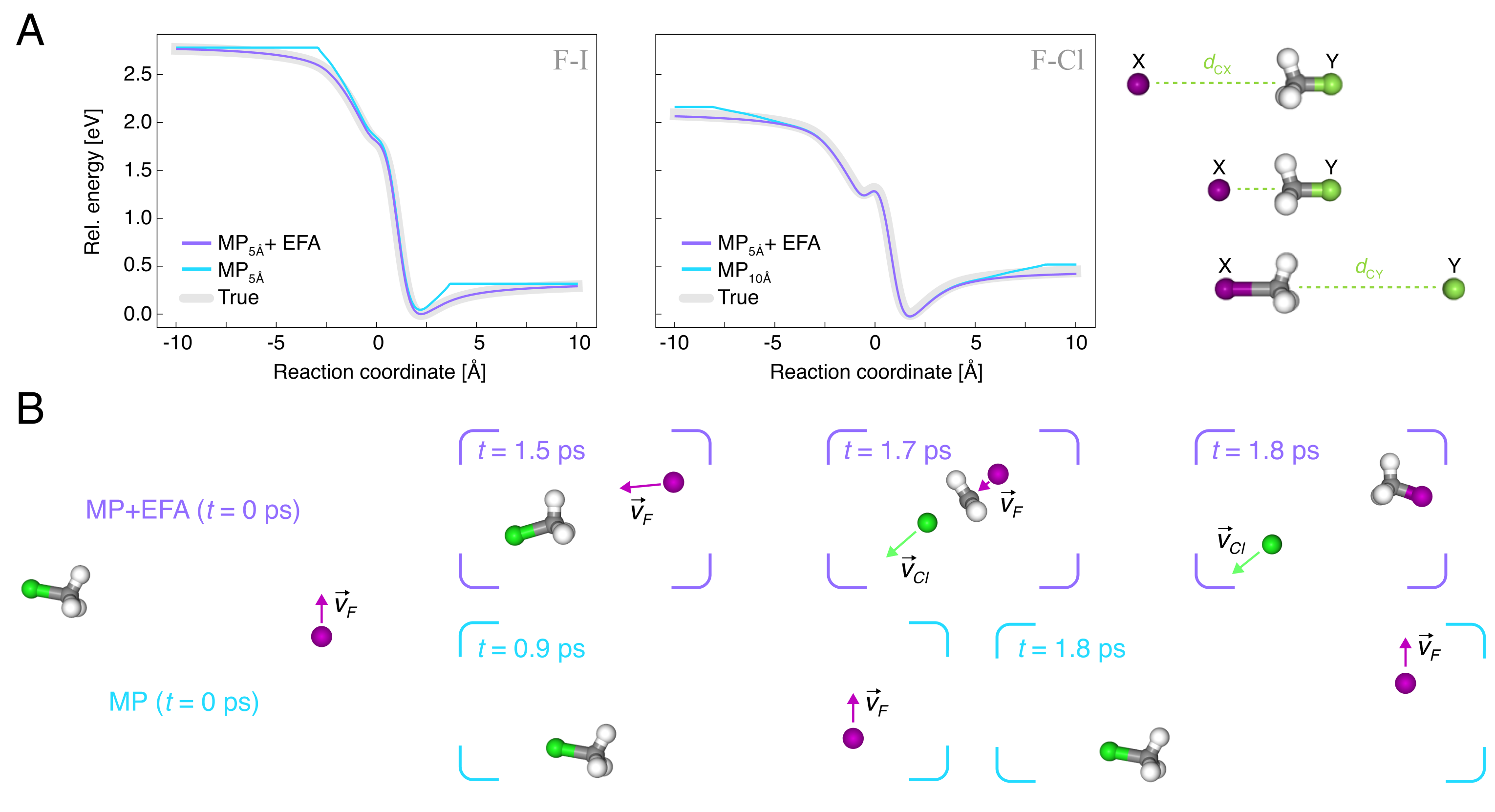
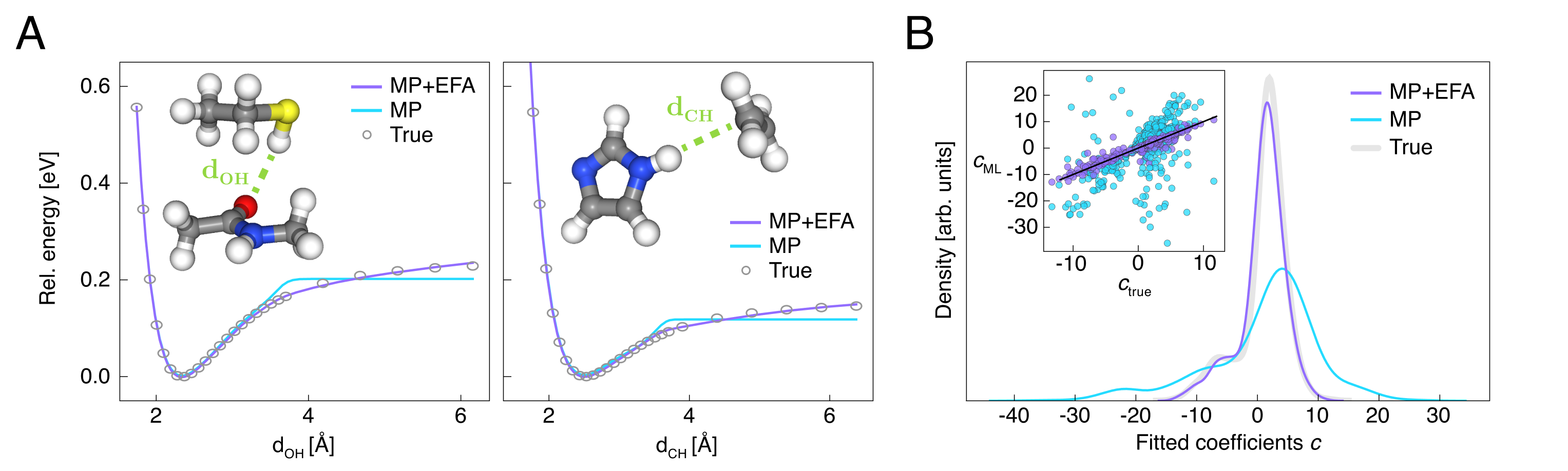
SN2 的结果最容易量化:在 局部模型上加入 EFA 后,能量与力的平均绝对误差分别下降约 和 。单纯把 cutoff 增大到 ,或者加入解析色散修正,都不足以恢复正确的长程渐近行为。图 4a 和 4b 进一步说明,这种差异不只是静态误差上的改进,而是直接影响反应动力学轨迹。二聚体实验得到的结论也很一致:纯 MP 在分子间距超过 cutoff 后迅速失真,而 MP+EFA 能较好重建 binding curve;若把长程尾部拟合为幂级数形式,MP 与真值的 Pearson 相关仅为 ,MP+EFA 则提高到 。
6.4 Cumulene 体系中的电子离域效应
前面的长程相互作用大多还能被理解为“距离函数”的修正,而 cumulene 例子测试的是更难的一类非局域效应:电子离域导致的构象能量变化。这里能量强烈依赖链两端 CH 转子的二面角 ,而这种依赖并不能由简单的 pairwise distance 充分刻画。
在配置上,作者选取链长 的 cumulene,比较 与 的 MP,以及 的 MP+EFA,其中 EFA 分别使用 三种最高阶数。除了静态势能面外,作者还进一步做了 、 的 MD 模拟,并检查由动力学得到的构象分布与功率谱。
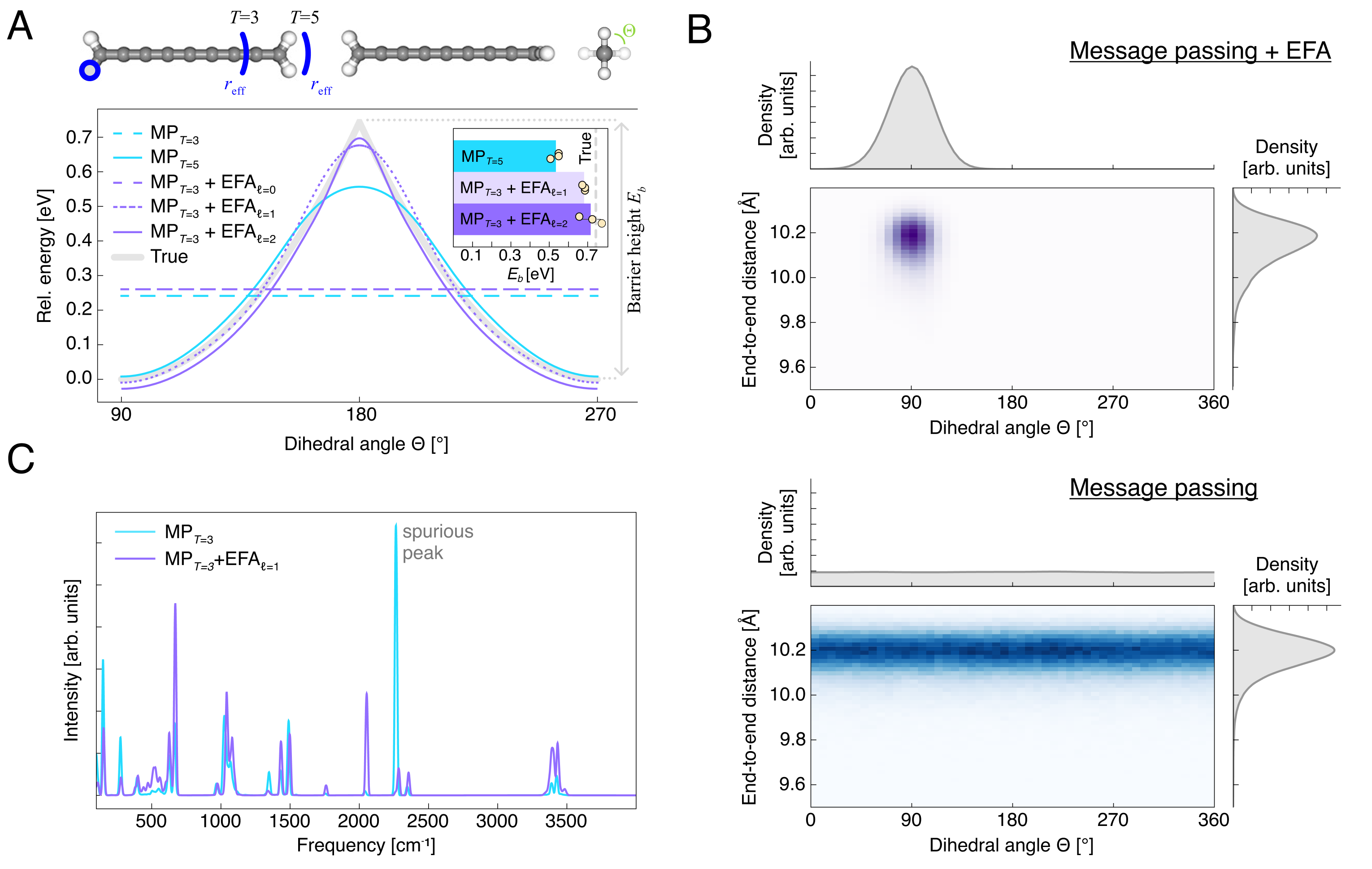
这一组结果把“为什么需要等变 EFA”讲得非常清楚。只用不变特征的 MP+EFA 仍然失败,因为它本质上依赖 pairwise distance,无法稳定分辨二面角变化;一旦允许 的等变表示进入 EFA,势能障碍就能够被正确恢复,而且更高阶的 会进一步改进 barrier 预测。纯 MP 即使把层数加到 ,也仍然低估势垒,作者把这归因于 over-squashing。更关键的是,这种静态误差会直接传到动力学上:MP+EFA 预测二面角分布集中在 附近,而纯 MP 给出几乎平坦的分布,并在功率谱中产生明显的伪峰。
6.5 实验结论的适用边界
第 6 节所有实验合起来,支持的是一个相当克制的结论:EFA 在“全局、长程、缓变”的相关上确实系统性优于严格局部模型,但它并不意味着局部结构已经不重要。作者还专门测试了一组以局部相互作用为主的材料体系,结果显示 MP 与 MP+EFA 的表现大体相当。这说明 EFA 的主要价值不是在任何任务上都一概提高精度,而是在真正存在跨 cutoff 相关时提供必要的全局通道。
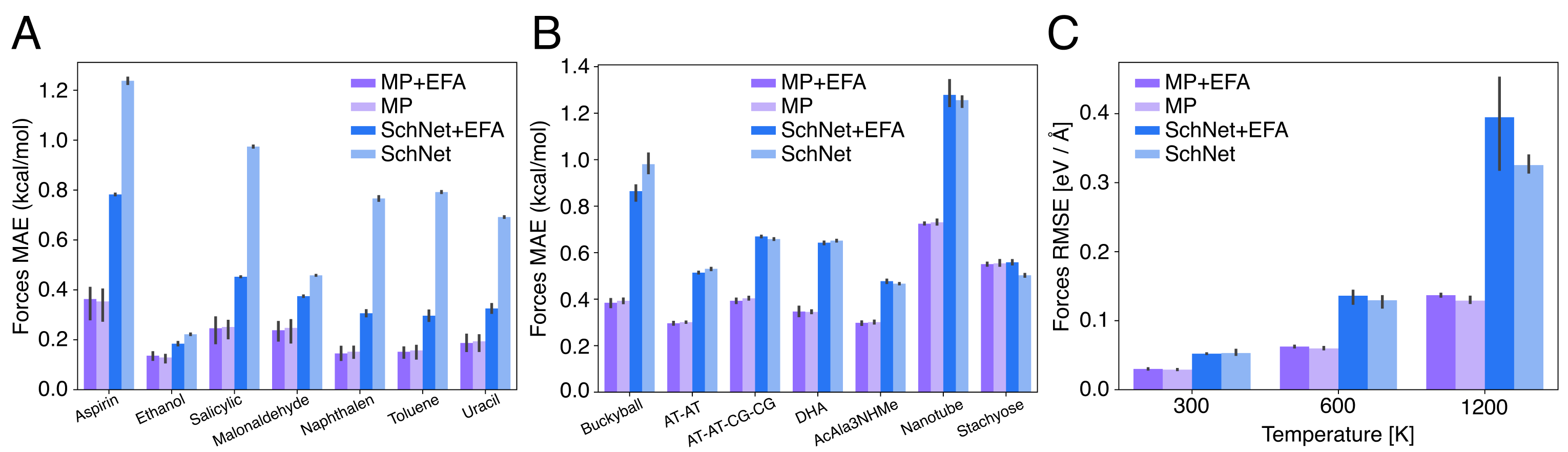
这一点和第 5 节的数值分析是连在一起的。EFA 依赖球面积分与有限网格近似,因此更适合描述低频、随距离缓慢变化的非局域效应;如果把它单独拿来处理强烈、短程、快速变化的化学相互作用,既不经济,也未必稳定。作者因此反复强调,最现实的用法不是“用 EFA 取代局部模型”,而是“用 EFA 去增强已有的局部架构”。从实验部分看,这个判断是成立的:凡是长程结构真正重要的场景,收益最明显;而在局部主导的场景,EFA 至少不会系统性破坏性能。
7 总结与评述
7.1 这篇工作的核心贡献
如果只用一句话概括,这篇工作的真正贡献并不是“又提出了一种 attention 变体”,而是给出了一个相当完整的构造:如何在保持近线性复杂度的前提下,把全局欧氏几何信息注入原子表示,并且不破坏机器学习力场所要求的几何对称性。这个贡献同时发生在表示、算法和应用三个层面。
在表示层面,ERoPE 回答的是一个此前并不容易处理的问题:线性 attention 需要 query-key 核具备可分解性,但原子体系真正重要的却是相对位移这一 pairwise 量。作者的做法是把绝对坐标编码进相位,让相对位移在内积中自动出现;这样几何关系不再以显式的 距离矩阵形式进入模型,而是以内积结构的方式被恢复出来。这个观察本身就具有方法论意义。
在算法层面,EFA 把这种相位编码与线性 attention 的“先聚合 key-value,再由 query 读取”的计算顺序结合起来,从而避免了标准 self-attention 的二次复杂度。它不是通过截断全连接图来获得线性标度,而是通过重排张量收缩顺序来实现这一点。对需要同时处理上万原子的体系而言,这是比单纯“多加几层局部 message passing”更有结构性的改进。
在应用层面,作者并没有只在标准 benchmark 上追求一个更低的 MAE,而是有意识地挑选了几类传统局部模型最容易失真的场景:离子体系中的长程库仑尾部、SN2 反应中的远程作用、非共价二聚体中的 binding curve,以及 cumulene 中的电子离域。实验部分真正支持的结论是:EFA 并非一个通用的“精度放大器”,但它确实为局部模型补上了一条此前缺失的全局几何通道。
7.2 方法设计中的关键洞见
从理论结构看,EFA 最有价值的地方在于它把三个通常彼此冲突的要求放进了同一个框架:全局交互、欧氏几何、线性复杂度。以往这些要求往往只能两两兼得。标准 self-attention 易于处理全局交互,也容易显式写入 pairwise 几何,但代价是二次复杂度;局部等变卷积天然尊重几何对称性,也具备线性标度,但其有效感受野仍受局部图结构约束;普通线性 attention 则具备复杂度优势,却缺少一个自然的几何入口。EFA 的意义就在于,它不是在已有三者之间做折衷,而是试图重新安排问题的表述方式。
更具体地说,ERoPE 的相位构造把“相对几何只能通过显式 pairwise 特征进入模型”这一习惯打破了。经过这一改写后,距离与方向信息不再只是输入图上的边属性,而是成为 query-key 兼容性的一部分。再经过球面积分与球谐展开,EFA 最终得到的也不只是一个带有位置编码的注意力层,而是一个与等变卷积在形式上紧密相关的全局积分算子。就这一点而言,把 EFA 简单理解成“欧氏空间版本的 Transformer attention”其实是低估了它;更准确的说法是,它位于注意力机制、平面波展开和等变卷积之间的交叉地带。
不过,这种优雅也伴随着一个需要澄清的事实:EFA 并不是严格意义上“显式方向化的 attention”。它的核心兼容性仍然来自标量型的 query-key 收缩,方向等变信息主要通过球谐基与输出结构进入。这一点并不削弱方法的有效性,但它有助于我们更准确地理解 EFA 的表达机制:它更像一个全局、几何敏感的等变积分核,而不是一个每一对原子都拥有方向张量权重的注意力矩阵。
7.3 与相关路线的关系
EFA 与标准 self-attention 的关系最直接。二者都让每个节点在一次更新中访问全体节点,也都依赖 query、key 与 value 的分工;但标准 self-attention 的几何信息通常以显式 pairwise 项进入注意力核,而 EFA 则通过 ERoPE 把几何关系移入相位结构,并借此恢复与线性 attention 相容的计算顺序。与此同时,EFA 也放弃了 softmax 归一化所带来的概率解释,因此它并不是标准 attention 的简单近似,而是一个不同的全局聚合机制。
EFA 与局部等变 MPNN 的关系则更像互补,而非替代。NequIP、MACE、Allegro 一类方法的强项在于对短程相互作用和局部化学环境的高分辨率建模;EFA 并没有试图重写这一部分,而是把自己放在“非局域修正分支”的位置上。论文中最有说服力的实验恰恰说明:即使把局部 MP 的有效 cutoff 通过增加层数扩大到覆盖全系统,它也仍然不等价于一次真正的全局几何耦合。这意味着“更深的局部模型”与“显式的全局模型”在结构上不是同一件事。
和已有的非局域方法相比,EFA 的定位也相当清楚。像 SpookyNet 这样的模型虽然引入了线性标度的 non-local correction,但其全局交互并不真正解析欧氏相对位置与取向,因此在论文所挑选的几类几何敏感问题上会失败。另一条路线则是显式写入长程物理项,例如库仑、色散、Ewald 或 latent Ewald 类方法。这些方法的优点是物理归纳偏置更强、对特定相互作用更有针对性;缺点是通常假设了预定义的相互作用形式,或主要面向周期体系。EFA 的不同之处在于,它不预设长程作用属于哪一种物理项,而是学习一个更一般的全局算子。因此,它的泛化面更宽,但物理特异性更弱。
最后,从形式关系上看,EFA 与 Ewald-inspired 方法之间确实存在可比性,尤其是在周期体系和不变标量表示的简化情形下。二者都可以被理解为某种平面波或频域展开;差别在于,Ewald 类方法通常在倒空间向量上求和,并通过显式滤波器塑造频域响应,而 EFA 则通过方向积分、频率混合和 attention-like 通道交互形成其全局核。这种关系说明 EFA 并不是凭空出现的一条新路线,而是把频域长程建模与表示学习更紧地耦合在了一起。
7.4 局限性与开放问题
这篇工作的局限性首先来自数值积分本身。EFA 的线性标度是以 近似保持常数为前提的;一旦问题所需的频率范围变高、最大原子间距变大,或者希望更严格地保持旋转不变性与等变性,就可能需要增加 Lebedev 网格密度。此时,方法虽然仍优于显式二次复杂度的全连接 attention,但其“线性”优势会被逐步侵蚀。也就是说,EFA 的复杂度优势并不是绝对的,而是建立在一个“所需角向分辨率不过高”的假设之上。
第二,EFA 对方向信息的处理方式虽然优雅,但也带来表达边界。正如前面强调的,方向等变性主要通过球谐展开后的输出结构引入,而不是通过显式方向化的 attention 权重本身实现的;其核心 query-key 兼容性仍然是标量型收缩。这意味着 EFA 很可能更擅长表达“由全局几何诱导的平滑方向效应”,而未必是所有强各向异性、多体角向耦合的最直接表示。论文中的 cumulene 结果说明它已经足以处理相当微妙的电子离域,但这并不等于该表示在各类方向敏感问题上都已达到最优。
第三,EFA 目前最合理的定位仍然是局部模型的增强模块,而不是局部模型的替代品。无论从第 5 节的数值分析还是第 6 节的实验结果来看,它都更适合建模低频、缓变、跨 cutoff 的非局域相关;对强烈、短程、快速变化的化学相互作用,局部等变卷积和 message passing 仍然是更自然的主干。这一点其实也是这篇文章最成熟的地方:作者没有把 EFA 夸大成一个“统一解决长程问题”的终极模块,而是把它明确放在 hybrid architecture 的非局域分支上。
第四,周期体系中的版本虽然实用,但其对称性故事比非周期情形弱一些。对孤立体系,球面积分给出的旋转不变性是干净而统一的;对周期体系,作者转而利用晶格向量作为参考方向,这在物理上是合理的,但也意味着方法开始依赖额外的参考框架。对某些材料问题这完全不是缺点,但从理论统一性上说,周期版 EFA 并不像非周期版那样“闭合”。
最后,实验覆盖面虽然有针对性,但仍然不是穷尽式的。作者挑选的例子很好地证明了 EFA 的必要性,却还没有回答另一个问题:在更大规模、更复杂组成、更长时间尺度的真实生产级模拟中,EFA 的收益与开销比究竟如何。这不是对本文结论的否定,而是它留给后续工作的自然问题。
7.5 总体评价
整体来看,这篇文章最值得重视的地方,不是它在某个标准 benchmark 上把误差再压低了一点,而是它为“如何在线性复杂度下表达欧氏空间中的全局几何相关”提供了一个可操作、可分析、可验证的答案。ERoPE 给出了表示上的关键构件,EFA 给出了计算上的实现方式,而实验则说明这种结构性改动确实能在传统局部模型失效的地方发挥作用。
如果把它放到更宽的机器学习力场发展脉络中看,这篇工作的意义更像一次接口扩展:它没有推翻局部等变 MPNN,也没有取代物理启发的长程校正,而是在二者之间打开了一条新的路线。对后续研究而言,真正值得继续推进的也许不是“把 EFA 原样接到更多 backbone 上”,而是沿着它暴露出来的几个核心问题继续前进:如何更自适应地选择频率与积分网格,如何把显式方向化的非局域权重引入线性框架,以及如何将学习得到的全局算子与更强的物理先验进一步结合。
附录
附录 A:EFA 与 Ewald 型长程方法的形式关系
在周期体系中,EFA 与 Ewald-inspired message passing 之间存在一个值得单独指出的形式联系。若只考虑不变标量特征,并把 Ewald 型更新写成最简形式,那么它可以表示为
这里 是由晶格导出的倒空间向量集合, 是定义在 上的可学习频域滤波器。这个表达式的结构很明确:先在频域上累积全局信息,再以平面波相位把它投影回每个原子位置。
若把 EFA 也限制在不变标量、去掉额外特征映射 、并把方向积分替换为有限方向求和,则其最简形式可写为
如果进一步把频率与方向选取得足够特殊,使
那么式 (39) 和式 (40) 在结构上就会非常接近:二者都可以理解为“平面波基上的全局累积,再返回到原子位置”的频域长程更新。
但二者并不等价。Ewald 型方法的求和对象是由晶格决定的倒空间向量,且通常带有显式的频域滤波函数;EFA 的求和对象则是方向与频率的组合,其全局核还要经过 query、key 和 value 的通道交互来形成。前者更接近带有明确物理频域结构的长程项,后者则更接近一个学习得到的、attention-like 的全局积分算子。二者在周期体系中有交叉,但在非周期体系中这种联系就不再成立。
附录 B:符号表
| 符号 | 含义 |
|---|---|
| 体系中的原子数 | |
| 第 个原子的三维坐标 | |
| 相对位移, | |
| 相对距离, | |
| 相对位移的单位方向 | |
| 单位球面上的辅助方向变量 | |
| ERoPE 中使用的频率参数 | |
| query、key、value 表示 | |
| 线性 attention 原型中的特征映射 | |
| 将 与 ERoPE 组合后的简写记号 | |
| 阶数为 的球谐函数向量 | |
| 阶数为 的 spherical Bessel function | |
| Lebedev 求积的球面网格点数 | |
| 第 个 Lebedev 网格点对应的求积权重 | |
| query/key、value 与球谐输出所使用的最大阶数 | |
| query/key 与 value 的特征维度 | |
| parity axis 的大小 | |
| 原子 的局部邻域 | |
| 局部分支与非局部分支的层映射 |